|
Boyang Zheng I'm currently an incoming PhD student at NYU Courant, advised by Saining Xie. I obtained my bachelor degree at Shanghai Jiao Tong University, ACM Honor Class. My current research interests include representation learning, generative modeling, and multi-modal learning. I have little interest in chasing the state-of-the-art unless I have to. Instead, I prefer to explore interesting ideas that help better understanding of this field or could possibly lead to new applications. Email / CV / Google Scholar / Github / Twitter |

|
News[2026-1] Enrolled as a PhD student at NYU Courant, advised by Saining Xie. [2025-6] Graduated from Shanghai Jiao Tong University with an Honor degree in Computer Science, ACM Honor Class. [2024-5] Internship begins! I'm now an intern at NYU VisionX Lab, advised by Saining Xie, doing research on generative models and MLLMs. I'll be on site at July, see you in New York! [2023-9] Internship begins! I'm now an intern at Shanghai AI Lab, advised by Chao Dong, doing research on MLLM and their possible applications on low-level vision tasks. |
Publications |
|
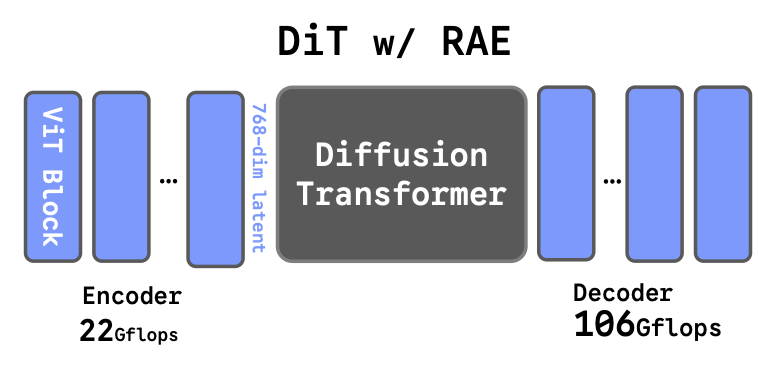
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, Saining Xie, arXiv, 2025 code / website / paper A class of autoencoders that utilize pretrained, frozen representation encoders as encoders and train ViT decoders on top. Training Diffusion Transformers in the latent space of RAE achieves strong performance and fast convergence on image generation tasks. |

|
LM4LV: A Frozen Large Language Model for Low-level Vision Tasks
Boyang Zheng, Jinjin Gu, Shijun Li, Chao Dong, arXiv, 2024 code / paper A careful designed framework to let a frozen LLM to perform low-level vision tasks without any multi-modal data or prior. We also find that most current MLLMs(2024.5) with generation ability are BLIND to low-level features. |

|
Targeted Attack Improves Protection against Unauthorized Diffusion Customization
Boyang Zheng*, Chumeng Liang*, Xiaoyu Wu, ICLR 2025 (spotlight) code / paper / public release for artists(also known as mist-v2) A method to craft adversarial examples for Latent Diffusion Model against various personlization techniques(e.g. SDEdit, LoRA), strongly outperforming existing methods. We aim for protecting the privacy of artists and their copyrighted works in the era of AIGC. |
|
This website is a modification of Jon Barron's Website. |