|
Boyang Zheng I'm currently a first-year CS PhD student at NYU Courant, advised by Saining Xie. I obtained my bachelor degree at Shanghai Jiao Tong University, ACM Honor Class. My research aims to understand the dynamics of high-dimensional, continuous, and often noisy data spaces. Representations, as a special form of data generated by neural networks, are particularly interesting to me. I'm specifically attracted to how to make predictions (of various types) on these representations and to model them efficiently. Concretely, I mainly work on (visual) representation learning, generative models, and multimodal learning. I also have some experience in low-level vision and adversarial examples. Email / Google Scholar / Github / Twitter |

|
News[2026-5] Internship begins! I'm now a summer intern at AMI Labs. [2026-1] New blog post (with Peter Tong): Lessons from Two Years of TPU Training in Academia — sharing hard-earned TPU debugging wisdom! [2026-1] Enrolled as a PhD student at NYU Courant, advised by Saining Xie. [2025-6] Graduated from Shanghai Jiao Tong University with an Honor degree in Computer Science, ACM Honor Class. [2024-5] Internship begins! I'm now an intern at NYU VisionX Lab, advised by Saining Xie, doing research on generative models and MLLMs. I'll be on site at July, see you in New York! [2023-9] Internship begins! I'm now an intern at Shanghai AI Lab, advised by Chao Dong, doing research on MLLM and their possible applications on low-level vision tasks. |
Publications |

|
Beyond Language Modeling: An Exploration of Multimodal Pretraining
Shengbang Tong*, David Fan*, John Nguyen*, Ellis Brown, Gaoyue Zhou, Shengyi Qian, Boyang Zheng, Théophane Vallaeys, Junlin Han, Rob Fergus, Naila Murray, Marjan Ghazvininejad, Mike Lewis, Nicolas Ballas, Amir Bar, Michael Rabbat, Jakob Verbeek, Luke Zettlemoyer†, Koustuv Sinha†, Yann LeCun†, Saining Xie† arXiv, 2026 website / paper A systematic study of unified multimodal pretraining with representation autoencoders and Mixture-of-Experts, showing how visual data complements language, enables world modeling, and benefits both understanding and generation. |
|
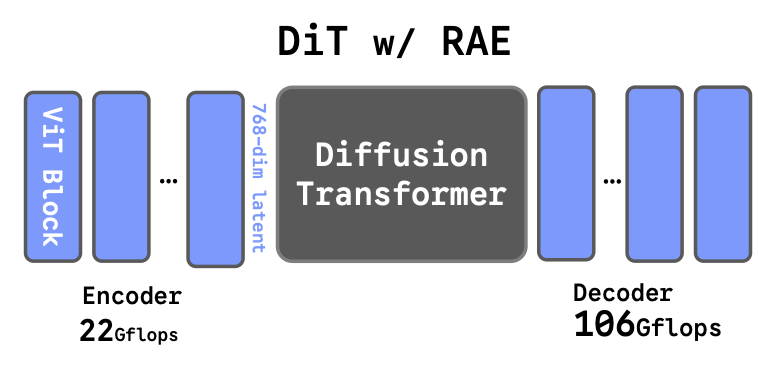
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, Saining Xie, ICLR, 2026 code / website / paper A class of autoencoders that utilize pretrained, frozen representation encoders as encoders and train ViT decoders on top. Training Diffusion Transformers in the latent space of RAE achieves strong performance and fast convergence on image generation tasks.
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders Scales the RAE framework to large-scale, freeform text-to-image generation and shows RAE-based diffusion transformers converge faster and generalize better than FLUX-style VAEs across model sizes.
Improved Baselines with Representation Autoencoders Improves RAE by aggregating the last k encoder layers and shows that RAE and REPA are complementary, enabling the same representation to serve as both encoder and target, achieving state-of-the-art results with faster convergence on ImageNet-256. |

|
LM4LV: A Frozen Large Language Model for Low-level Vision Tasks
Boyang Zheng, Jinjin Gu, Shijun Li, Chao Dong, arXiv, 2024 code / paper A careful designed framework to let a frozen LLM to perform low-level vision tasks without any multi-modal data or prior. We also find that most current MLLMs(2024.5) with generation ability are BLIND to low-level features. |

|
Targeted Attack Improves Protection against Unauthorized Diffusion Customization
Boyang Zheng*, Chumeng Liang*, Xiaoyu Wu, ICLR 2025 (spotlight) code / paper / public release for artists(also known as mist-v2) A method to craft adversarial examples for Latent Diffusion Model against various personlization techniques(e.g. SDEdit, LoRA), strongly outperforming existing methods. We aim for protecting the privacy of artists and their copyrighted works in the era of AIGC. |
|
This website is a modification of Jon Barron's Website. |